Урок 5.9: Алгоритмы JOIN — как база данных выполняет соединения
В предыдущих уроках мы писали SQL-соединения и сосредотачивались на том, какие данные они возвращают. Но как база данных на самом деле выполняет соединение под капотом? Понимание физических алгоритмов, которые использует движок, является ключом к написанию запросов с хорошей производительностью на больших наборах данных.
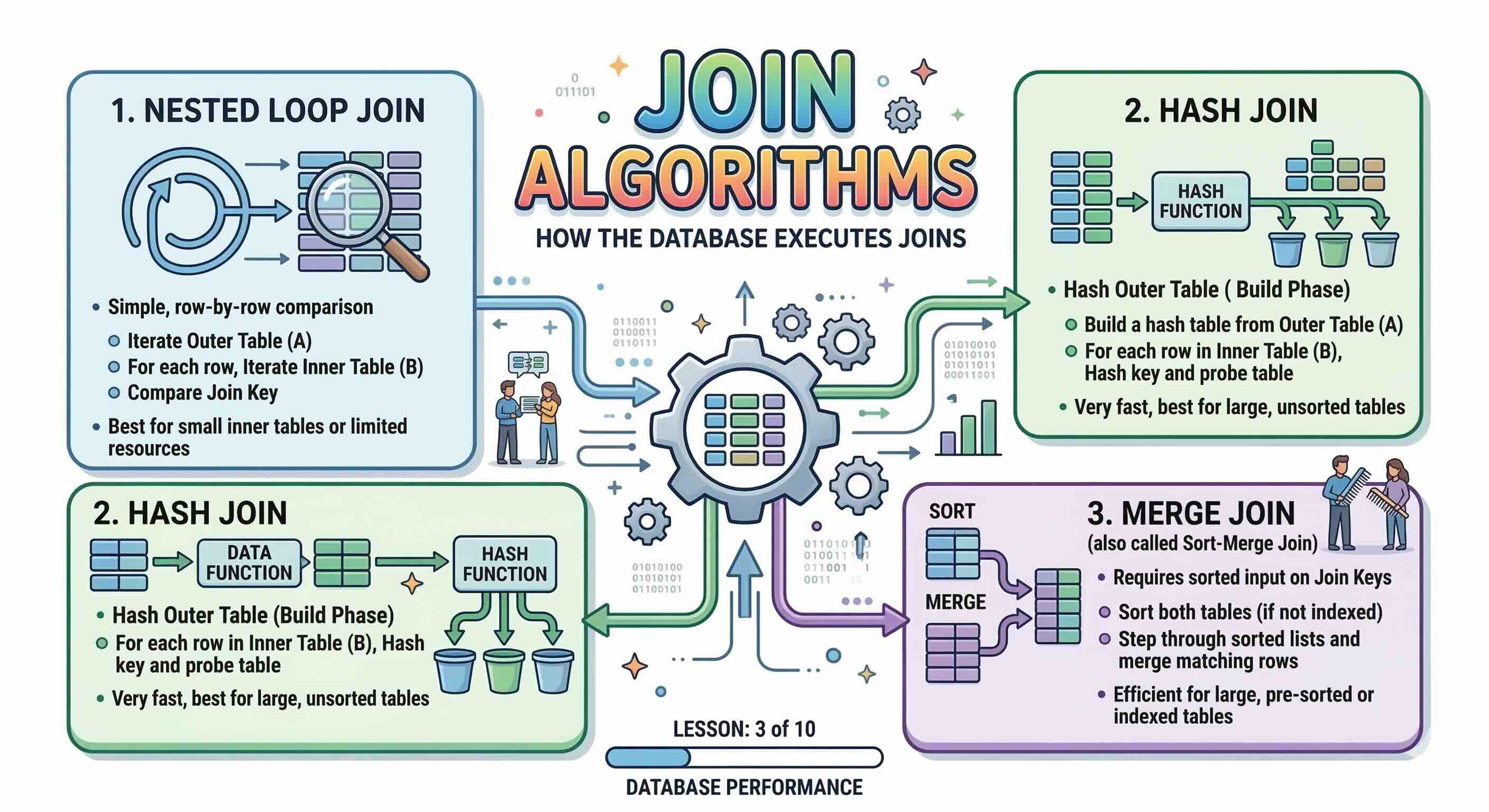
Три основных алгоритма соединения:
- Nested Loop Join (соединение вложенным циклом)
- Hash Join (соединение хешированием)
- Merge Join (соединение слиянием, или Sort-Merge Join)
Планировщик запросов выбирает алгоритм автоматически, исходя из размера таблиц, доступных индексов и объёма памяти. Мы не можем принудительно задать конкретный алгоритм в стандартном SQL, однако понимание компромиссов позволяет писать запросы и создавать индексы, направляющие планировщик к оптимальному выбору.
1. Nested Loop Join (соединение вложенным циклом)
Принцип работы
Nested Loop Join — простейший алгоритм. База данных выбирает одну таблицу как внешнюю (ведущую), а другую — как внутреннюю. Затем она перебирает каждую строку внешней таблицы и для каждой строки ищет совпадения во внутренней таблице — по сути, это два вложенных цикла for.
Концептуальный псевдокод:
for each row R1 in outer_table:
for each row R2 in inner_table:
if R1.key = R2.key:
output(R1, R2)
Когда на столбце соединения внутренней таблицы существует индекс, внутреннее сканирование превращается в быстрый поиск по индексу вместо полного перебора. Этот вариант называется Index Nested Loop Join и является одним из наиболее эффективных путей выполнения запроса.
Когда планировщик использует этот алгоритм
- Внешняя (ведущая) таблица мала.
- На столбце соединения внутренней таблицы существует индекс.
- Соединение использует условие неравенства (
<,>,BETWEEN) — Hash Join и Merge Join требуют равенства, поэтому Nested Loop является единственным вариантом в таком случае.
Преимущества и недостатки
| Nested Loop Join | |
|---|---|
| Преимущества | Работает с любым условием соединения, включая условия диапазона |
| Крайне быстр, когда внешняя таблица мала, а внутренняя индексирована | |
| Низкое потребление памяти — не требует построения вспомогательных структур данных | |
Начинает возвращать первые результаты немедленно (хорошо для запросов с LIMIT) | |
| Недостатки | Очень медленен на больших таблицах без индексов — O(N × M) в худшем случае |
| Производительность быстро деградирует по мере роста обеих таблиц |
2. Hash Join (соединение хешированием)
Принцип работы
Hash Join работает в два этапа:
- Фаза построения (Build phase): База данных читает меньшую таблицу и строит в памяти хеш-таблицу, ключом которой является столбец соединения.
- Фаза зондирования (Probe phase): База данных сканирует большую таблицу и для каждой строки выполняет поиск в хеш-таблице, чтобы найти совпадения.
Концептуальный псевдокод:
-- Фаза построения
hash_table = {}
for each row R1 in smaller_table:
hash_table[ hash(R1.key) ].append(R1)
-- Фаза зондирования
for each row R2 in larger_table:
for each match in hash_table[ hash(R2.key) ]:
if R2.key = match.key:
output(R2, match)
Это даёт общую сложность O(N + M) — линейную по размерам обеих таблиц — что делает алгоритм значительно масштабируемее, чем Nested Loop Join без индексов.
Когда планировщик использует этот алгоритм
- Соединяются две большие таблицы по условию равенства.
- На столбцах соединения отсутствуют полезные индексы.
- Доступно достаточно памяти для размещения хеш-таблицы (
work_memв PostgreSQL).
Преимущества и недостатки
| Hash Join | |
|---|---|
| Преимущества | Очень эффективен для соединений больших таблиц — O(N + M) |
| Не требует индексов на столбцах соединения | |
| Хорошо работает с несортированными, неупорядоченными данными | |
| Недостатки | Требует условия равенства — не применяется для диапазонных соединений |
| Требователен к памяти: если хеш-таблица не помещается в RAM, она сбрасывается на диск (значительно медленнее) | |
| Высокая стоимость запуска — необходимо построить хеш-таблицу, прежде чем вернуть первые результаты |
Примечание: в PostgreSQL можно управлять объёмом памяти с помощью параметра work_mem. Увеличение его значения снижает вероятность дорогостоящего сброса на диск при больших Hash Join.
3. Merge Join (соединение слиянием)
Принцип работы
Merge Join требует, чтобы обе входные таблицы были отсортированы по столбцу соединения. Затем алгоритм одновременно объединяет два отсортированных потока — очень похоже на финальный шаг классического алгоритма Merge Sort — продвигая указатель по каждому потоку для поиска совпадений.
Концептуальный псевдокод:
sort outer_table by key -- пропускается, если используется упорядоченный индекс
sort inner_table by key -- пропускается, если используется упорядоченный индекс
p1 = начало outer_table
p2 = начало inner_table
while не конец ни одного из потоков:
if outer[p1].key = inner[p2].key:
вывести совпадающие строки и продвинуть оба указателя
elif outer[p1].key < inner[p2].key:
продвинуть p1
else:
продвинуть p2
Ключевая оптимизация: если таблица может быть просканирована через упорядоченный индекс, шаг сортировки становится бесплатным, и Merge Join превращается в один из наиболее эффективных доступных алгоритмов.
Когда планировщик использует этот алгоритм
- Обе таблицы большие и условие соединения — равенство.
- Обе таблицы уже отсортированы, либо обе могут быть просканированы через упорядоченный индекс.
- Запрос уже требует
ORDER BYилиGROUP BYпо столбцу соединения (сортировка всё равно произойдёт).
Преимущества и недостатки
| Merge Join | |
|---|---|
| Преимущества | Очень эффективен для больших таблиц при наличии предварительной сортировки или упорядоченного индекса |
Возвращает результаты в отсортированном порядке, что может устранить необходимость в последующем ORDER BY | |
| Стабильное, предсказуемое потребление памяти | |
| Недостатки | Требует только условия равенства |
| Дорогостоящий явный шаг сортировки, если ни одна таблица не отсортирована и индекс недоступен | |
| Менее гибок, чем Hash Join, при работе с полностью неупорядоченными данными |
4. Выбор правильного алгоритма
Планировщик запросов выбирает алгоритм автоматически. Вы влияете на это решение косвенно — создавая правильные индексы и настраивая параметры памяти.
| Сценарий | Вероятный алгоритм |
|---|---|
| Маленькая внешняя таблица + индексированная внутренняя | Nested Loop Join |
| Две большие таблицы, равенство, без полезных индексов | Hash Join |
| Две большие таблицы, равенство, обе отсортированы / индексированы по порядку | Merge Join |
Условие неравенства (<, >, BETWEEN) | Nested Loop Join (единственный вариант) |
Практические советы:
- Создавайте индексы на часто используемых в соединениях столбцах внешних ключей — это обеспечивает быстрые Index Nested Loop и Merge Join.
- Если Hash Join сбрасывает данные на диск, рассмотрите увеличение
work_memили пересмотр структуры запроса. - Используйте
EXPLAIN ANALYZEдля проверки того, какой алгоритм был фактически выбран планировщиком и сколько времени заняло каждое шаг:
EXPLAIN ANALYZE
SELECT a.first_name, a.last_name, f.title
FROM actor AS a
INNER JOIN film_actor AS fa ON a.actor_id = fa.actor_id
INNER JOIN film AS f ON fa.film_id = f.film_id;
Ищите ключевые слова Hash Join, Merge Join или Nested Loop в плане выполнения, чтобы определить выбранный алгоритм и его стоимость.
Основные выводы урока
- Nested Loop Join перебирает строки во вложенных циклах — быстр для малых таблиц с поддерживающими индексами, очень медленен на больших неиндексированных таблицах; единственный алгоритм, поддерживающий условия неравенства.
- Hash Join строит хеш-таблицу в памяти из меньшей таблицы и зондирует её — эффективен для соединений больших неиндексированных таблиц по равенству, но требователен к памяти.
- Merge Join одновременно читает два предварительно отсортированных потока — идеален, когда данные уже упорядочены (например, через индекс) и соединение по равенству; возвращает результаты в отсортированном виде как бонус.
- Все три алгоритма поддерживают соединения по равенству; только Nested Loop также поддерживает условия диапазона.
- Вы влияете на выбор планировщика через индексы, настройки памяти (
work_mem) и структуру запроса — не через явное указание алгоритма в SQL. - Всегда используйте
EXPLAIN ANALYZEдля проверки фактически применяемого алгоритма и выявления узких мест по времени выполнения.